第八届浙江省大学生网络与信息安全竞赛 初赛 DontDebugMe
DontDebugMe
真·纯萌新教学
下载得到DontDebugMe.exe,一个让你输flag的程序。
这类题目的本质:
用户输入 → 加密变换 → 与存储的加密数据比较 → 判断对错
所以我们的逆向过程就是:
存储的加密数据 → 逆向解密 → 得到原始flag
这种方法其实可以想象成你在编写一个「注册机」,或者简单的说,去破解某个付费软件的密钥。而这个密钥其实是已经在程序里写好了,但是是加密之后的,如果用户输入的密钥经过加密之后与那个加密的相同,那么就说明密钥是正确的。
好吧,让我们使用ida。
打开之后先看看main函数。在左侧的function name栏中选定main。
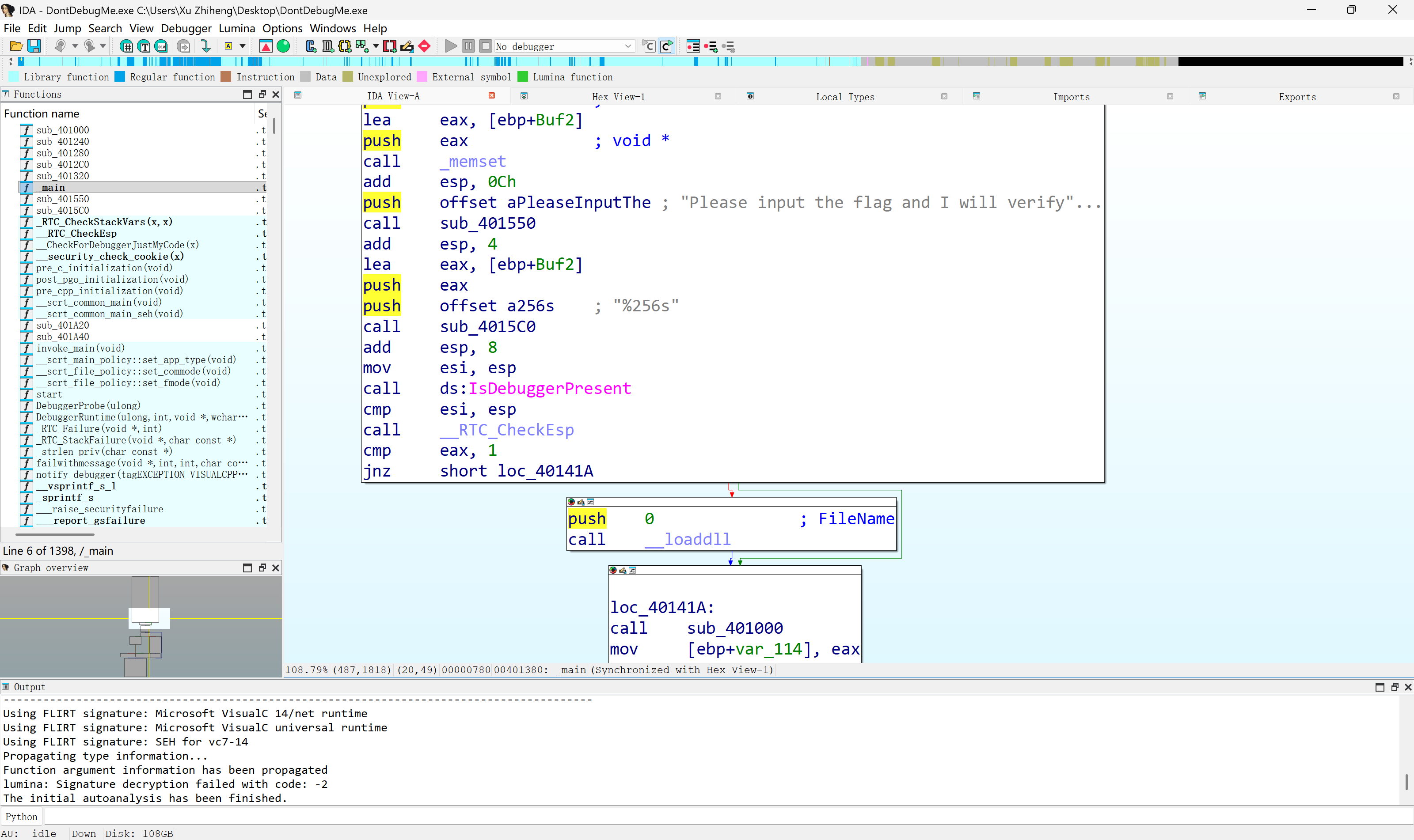
很明显,这里就是程序的核心部分。当然,也可以使用Shift+F12显示所有的string,通常包含“flag”的地方就是突破口。
我们继续,使用ida的超模功能——生成伪代码。按F5。
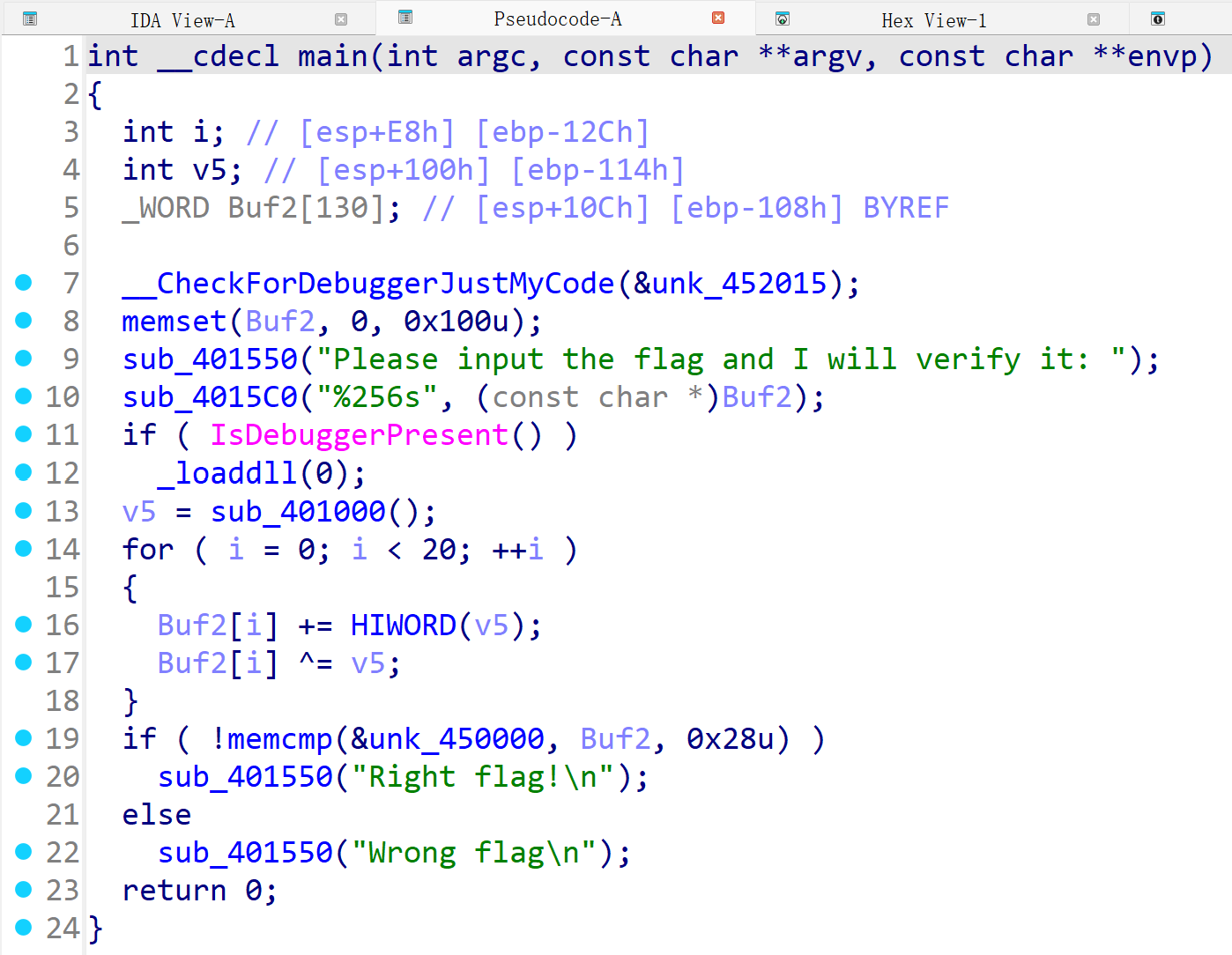
这时候这道题的思路已经明晰了。但鉴于我是纯萌新,这里的一切对于我来说都是陌生的。我们可以遵循逆向的原则,从后往前看(其实我做的时候是从前往后的,不过从后往前更符合逻辑)。这里的if可以说是最重要的部分了,就是它来判定flag是否正确的。
就让我们详细地看一看if ( !memcmp(&unk_450000, Buf2, 0x28u) )。上网查找,得知这里的memcmp在后面的比较值相等的时候返回0;自然,!memcmp就返回1,为真值,就输出“Right flag”了。那&unk_450000, Buf2又是啥呢?我们可以双击这个unk_450000地址,然后就能看到对应的很多data:
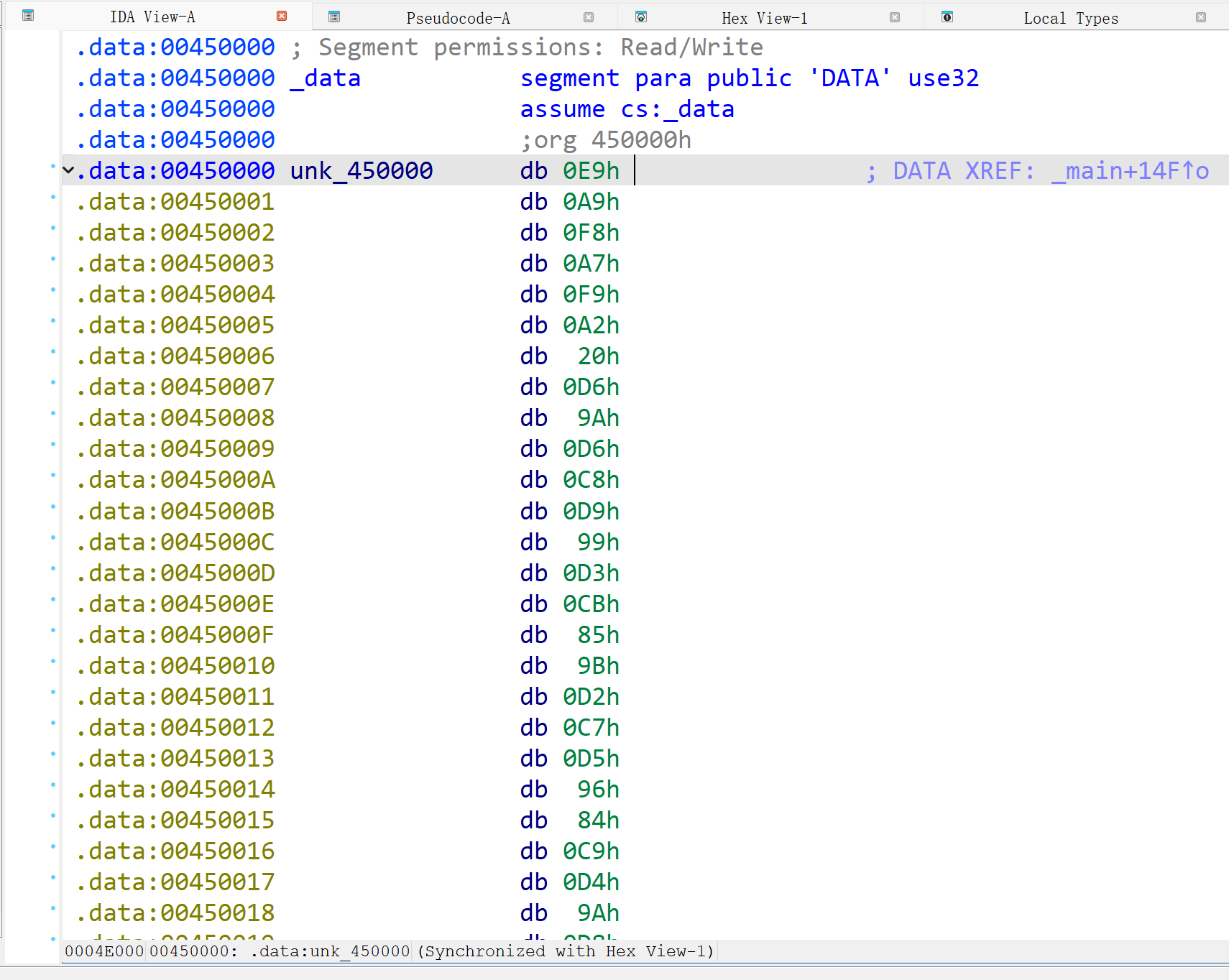
啊,那这个应该就是加密之后的数据了,我们就是要对它进行操作。此时unk_450000与Buf2相等(Buf2也就是对你输入flag的加密结果),那我们就可以去看看Buf2究竟遭受了什么?
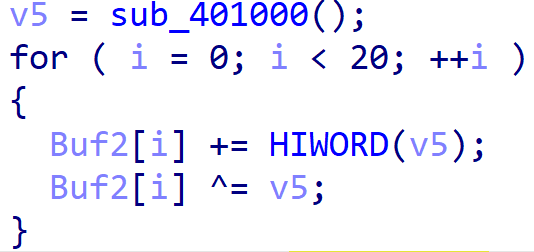
很明显,Buf2是与一个叫v5的家伙进行了某种交易。所以现在我们的任务就是先去把v5的内容揪出来。
v5等于sub_401000()。但是点进这个sub_401000()函数,你就会发现这儿不好办了。太复杂了!
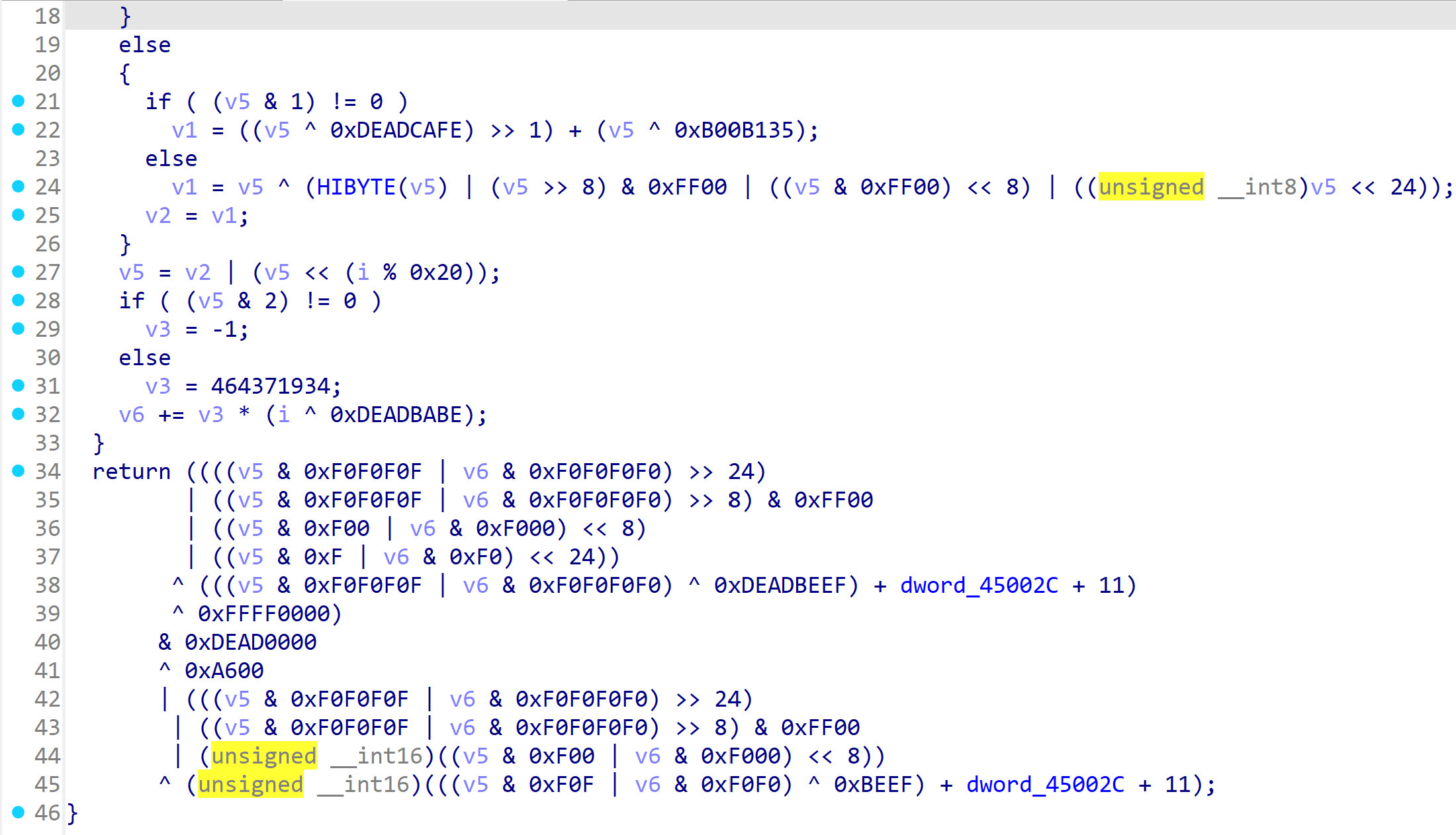
所以我们就可以采用调试的方法去把这个sub_401000()的值读出来。但是哪有那么一帆风顺?我们可以发现,这个程序有着一个检测是否在调试的东西:

通过追踪这个_loaddll(0),可以知道一旦被发现处于debug模式下,那么这个程序就会退出。这,也许就是DontDebugMe这个题目的意思罢!
所以我们面临着新的挑战:反反调试。学长告诉我,这个题目用汇编jz跳转的知识和改zf标志位的方法最快速。
让我们去看看汇编代码。
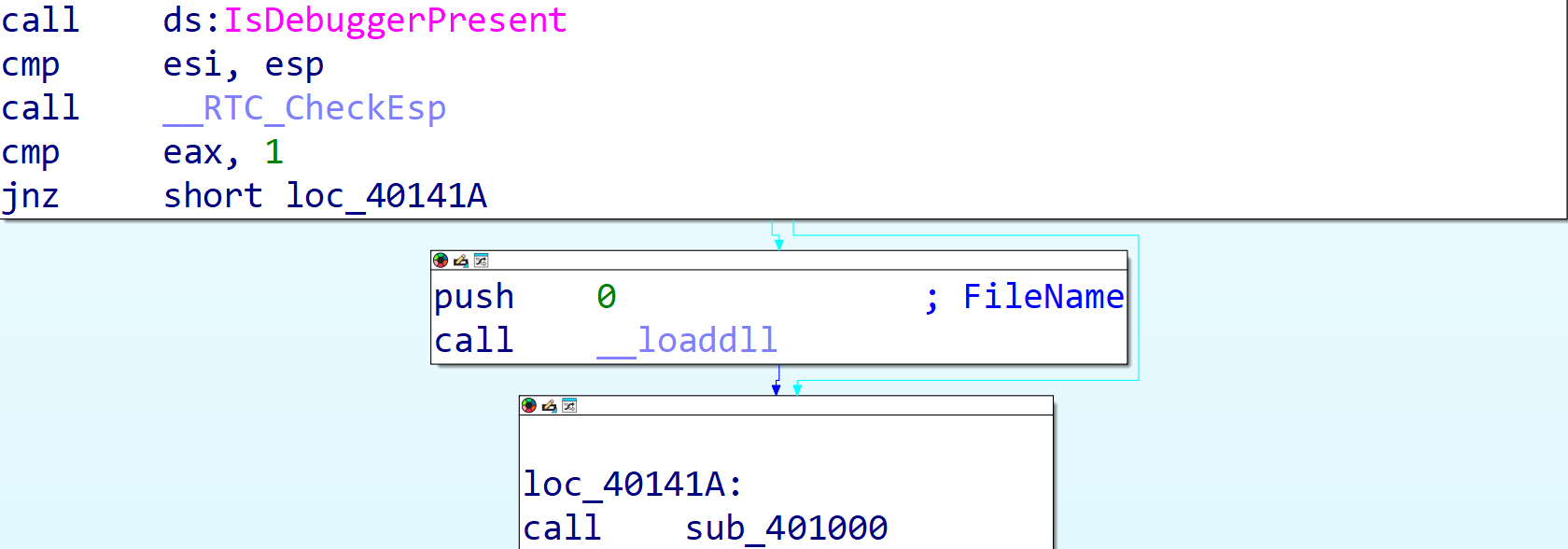
我们可以发现,这里有一个IsDebuggerPresent函数。通过上网查阅,我得知其作用为检测到debug时返回1。这个1被放到了eax寄存器中。然后进行了eax与1的cmp,使得ZF(zeroflag)为1。这里补充一点,cmp的本质实际上是对eax和1进行相减,结果为0则将ZF置为1(true),否则为0。
那jnz又是什么意思呢?实际上很好理解,就是"jump if not zero"的意思了。那现在我们使用调试器,ZF为1(换句话说,zeroflag为真),说明确实是zero,那么就不会进行“jump”了。
我们需要进行调试,但是进行调试又会使程序退出。这时就需要用到改zf标志位的方法了。也就是说,在调试过程中在分叉路口之前停一下(打一个断点),做一个“变轨”的操作,让任何情况(本题中,有debug的情况下)都沿着一条可以走下去的路去执行,来改变不得不走一条断头路的局面。
开始debug。ida在一个一个函数之间的箭头可以让我们直观地看到现在到底是“往哪走”。
先把断点打在jnz处。按F2就好了。

运行,随便打点什么都行,因为我们只是需要读取sub_401000()的值。按下enter,你会发现这个红色箭头在闪(截屏截不到,反正就是这里)
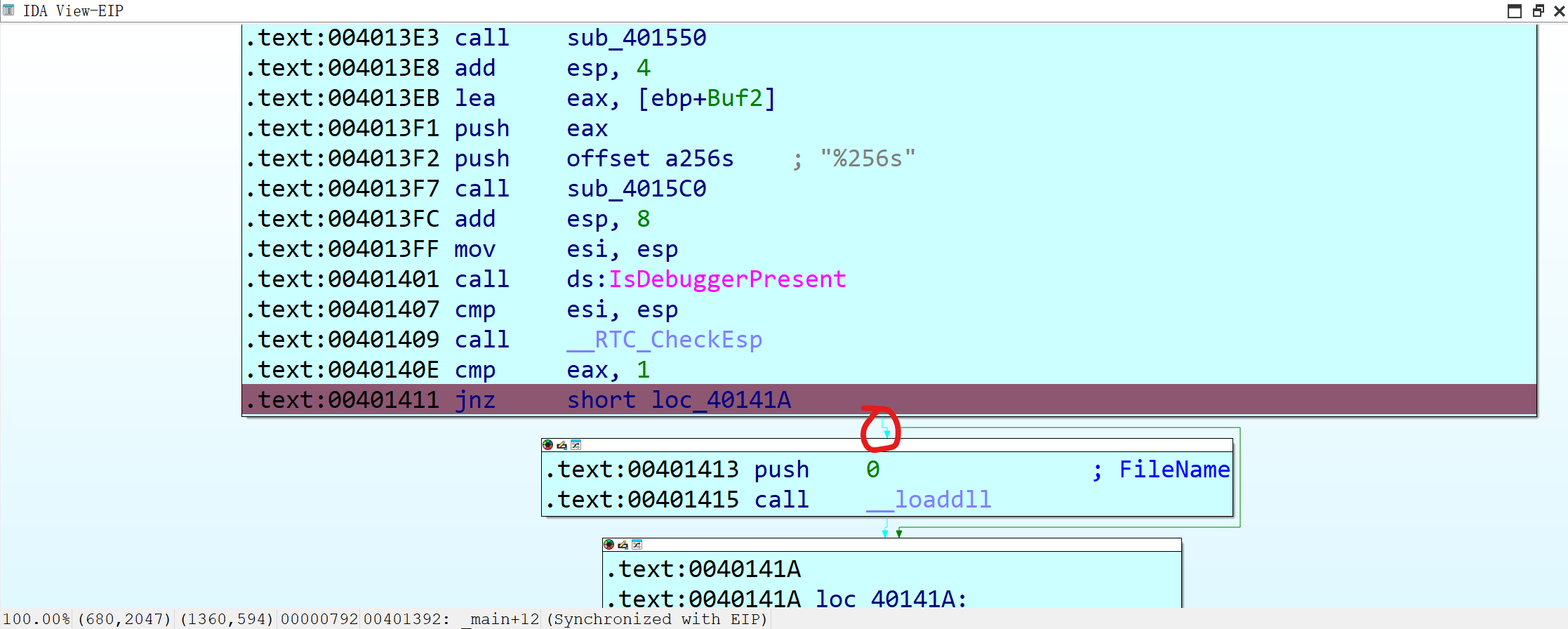
这说明此时jnz并没有jump,所以我们需要改zf标志位。zf的数值在右上角的小框里。
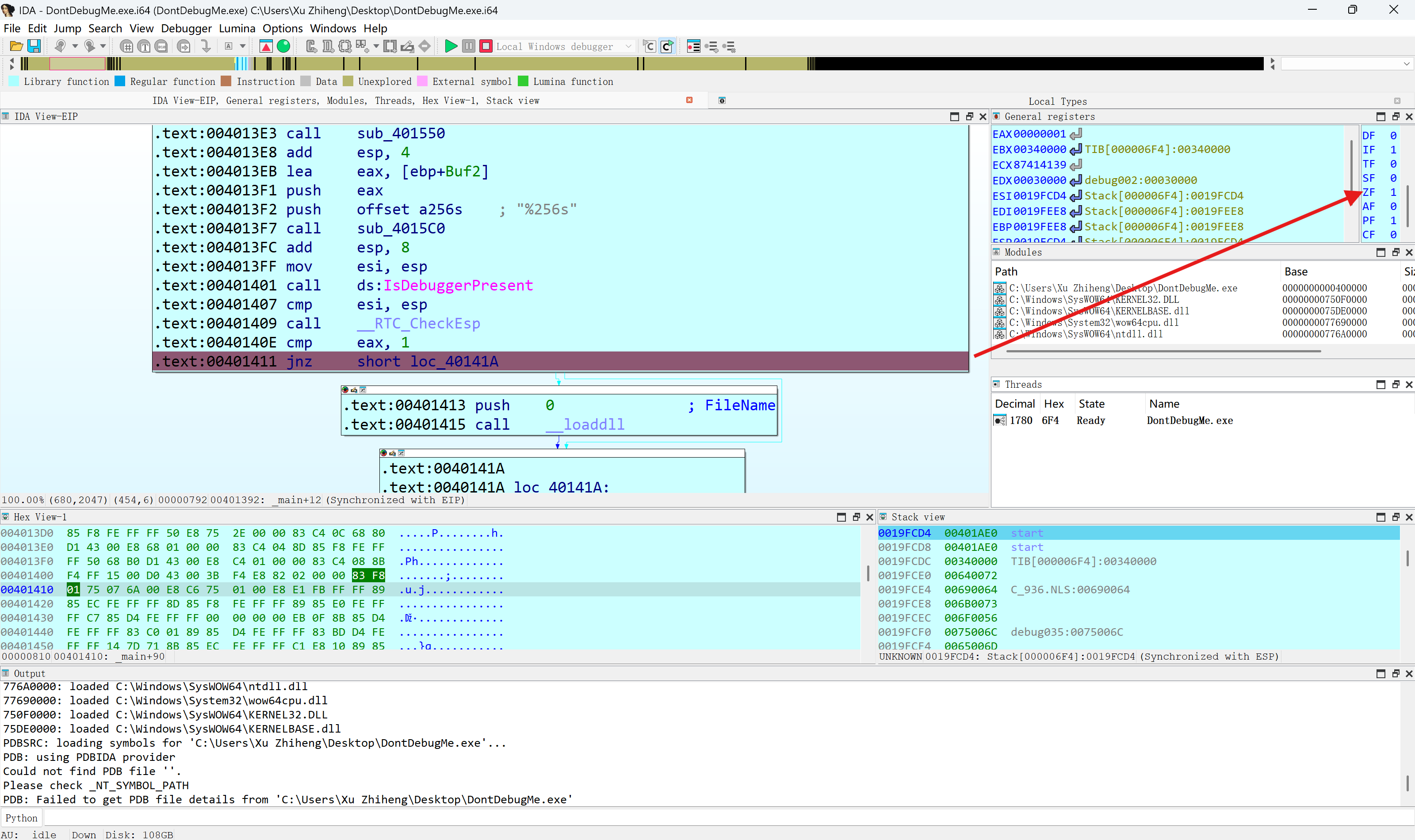
双击小框里的zf,将其改为0x0。这时,变成了这个绿色箭头在闪。
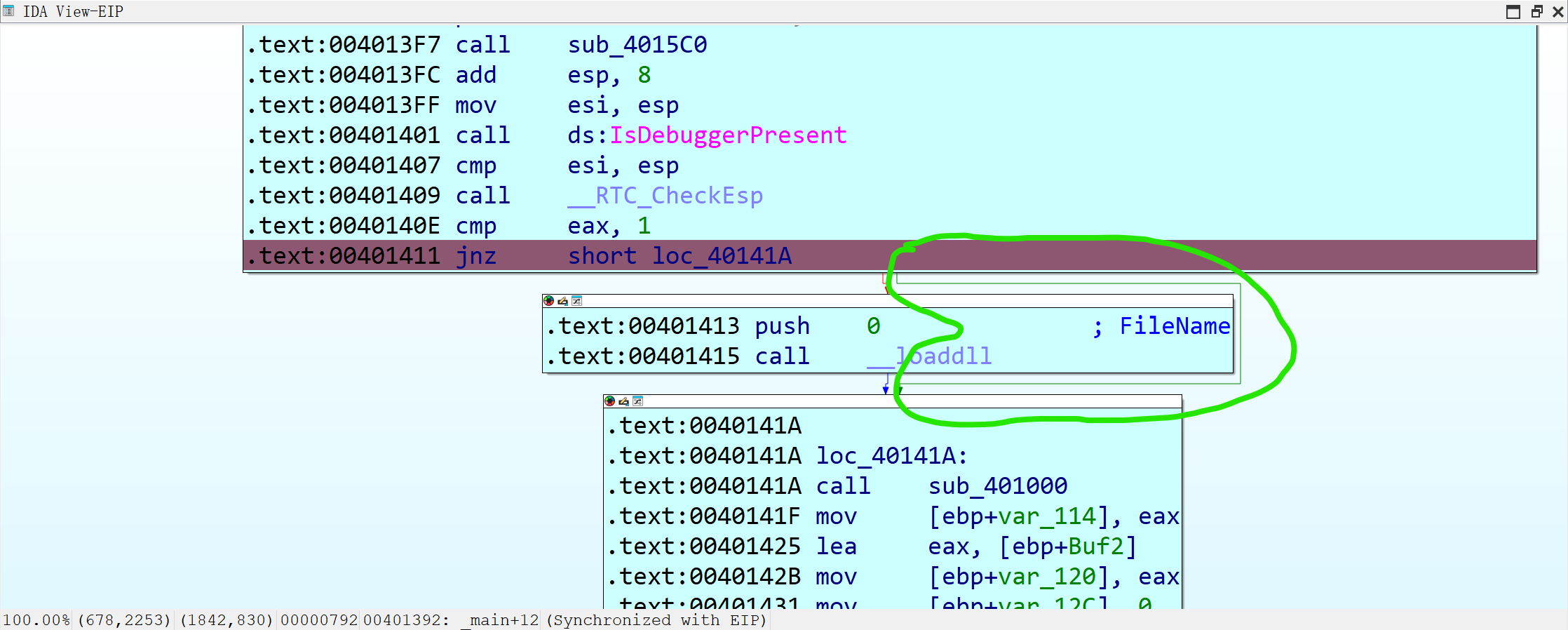
这样,我们就已经绕过了反汇编这一道门槛!
然后别急着退出调试,我们的任务是读出sub_401000()的值。从汇编代码中,我们可以看到,sub_401000的值被存储到了eax当中。所以,我们应该在mov eax后面打上断点,然后点击继续运行。(实际上,这里打在mov eax前面也是可以的,ds说是eax已经有了正确的返回值🤔)于是,sub_401000()的值就被我们读出来了。

万事俱备,接下来就应该回到伪代码,进行解密脚本的编写了。
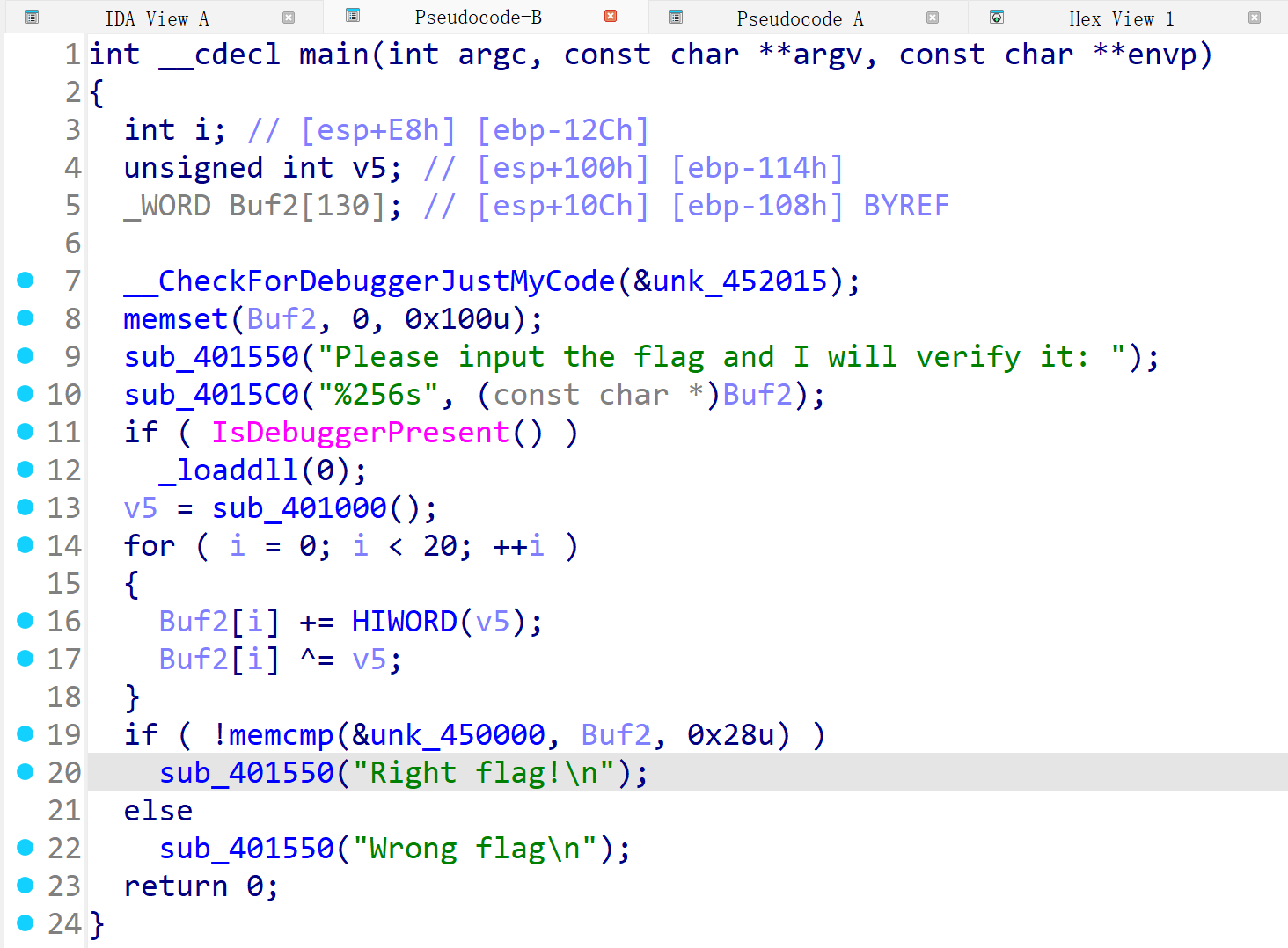
我们可以清楚地看出加密的过程:
原始值先与v5的高16位进行相加,然后再与v5异或。这里必须注意,第五行中把原始值定为一个16位值(_WORD),但是读出的eax是32位的,所以在Buf2[i] ^= v5这里,buf2_value (16位) 先是被提升为32位,进行32位异或运算,然后再被截断为16位(舍弃高16位)。
我们应该把这个顺序进行逆向操作。
首先,我们需要读出unk_450000地址的data。这已经在本文开头讲了,但是怎么把data导出来呢?(其实你也可以手敲😋)
很简单,只要选中这些数据,然后Edit>>Export Data就可以了。
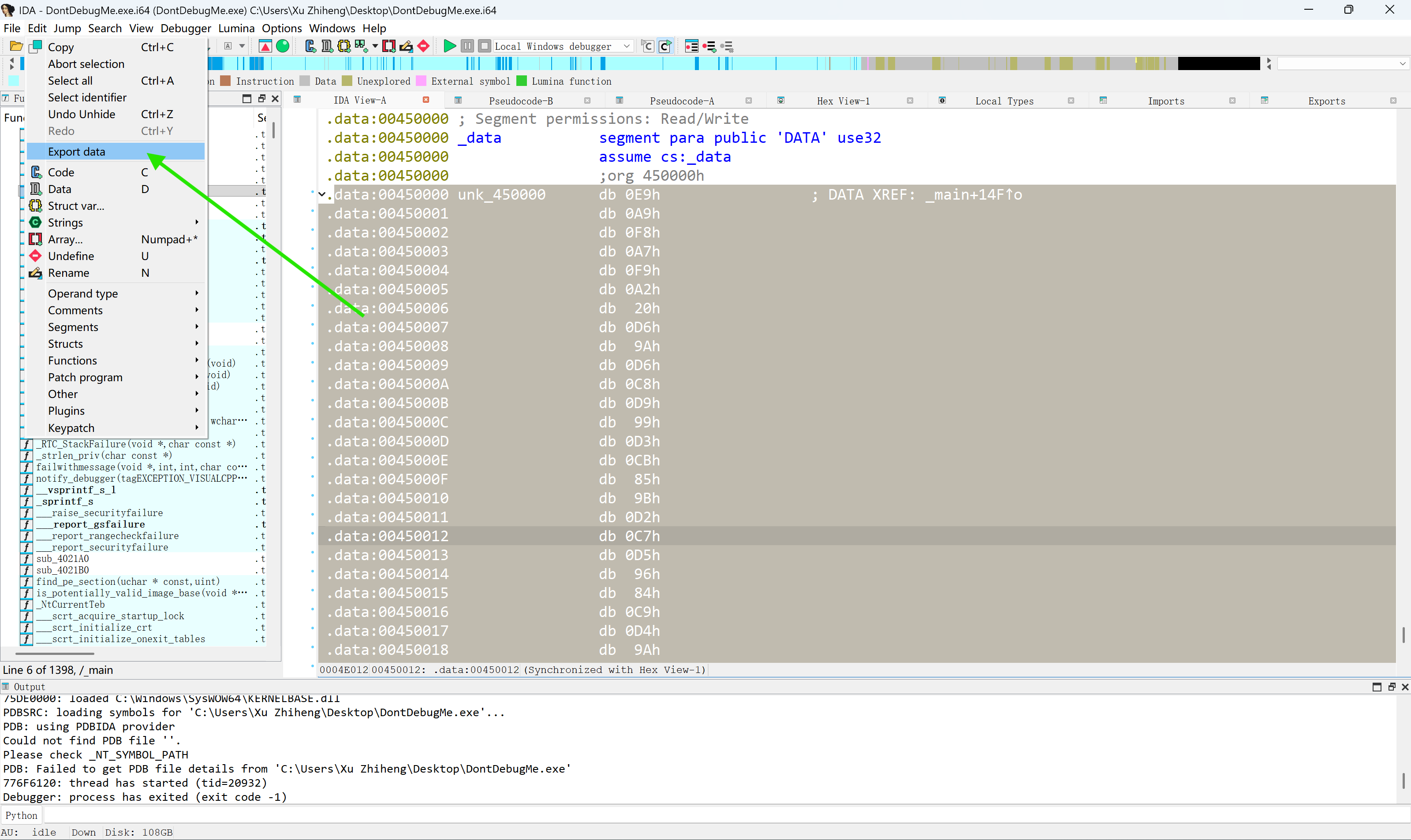
但是但是,这里面的data不仅是8位的,而且还是小端序。
关于大小端序在这里贴一张图,一目了然:

这就需要我们对这些data进行一个处理,例如,把0E9h和0A9h合并为0xA9E9。这里让d老师帮我写了一个脚本:
1 | def little_endian_to_words(hex_string): |
1 | 输出: 0xA9E9, 0xA7F8, 0xA2F9, 0xD620, 0xD69A, 0xD9C8, 0xD399, 0x85CB, 0xD29B, 0xD5C7, 0x8496, 0xD4C9, 0xD89A, 0xD7CA, 0xD59C, 0x85C8, 0xD597, 0x859E, 0xD49C, 0x6DCA |
这样,我们就可以进行进一步的解密了。
1.根据异或的可逆性,我们将加密的data与v5进行异或。
2.同样的,我们把得到的结果进行舍弃高16位,即&0xFFFF。
3.然后再减去v5的高16位,即-(v5 >> 16)。
最后,我们需要转换为ASCII字符输出。因为我们解密出来的每一个数据是16位,即两个字节的,所以我们需要进行一个“先拆再并”的操作:
1 | for i in range(20): |
所以,我们最终的解密脚本就长这样子:
1 | v5=0x0685EE20 |
运行,就得到了flag。

虽然这道题是入门题,官方的wp也只有寥寥几行,但是对于我这个新手来说还是有点挑战的,所以我写了这样一篇自认为详尽的wp,从中我也学到了很多😋
- Title: 第八届浙江省大学生网络与信息安全竞赛 初赛 DontDebugMe
- Author: Realknow
- Created at : 2025-11-27 11:26:19
- Updated at : 2026-02-23 16:48:03
- Link: https://realknowtech.github.io/2025/11/27/第八届浙江省大学生网络与信息安全竞赛-初赛-DontDebugMe/
- License: This work is licensed under CC BY-NC-SA 4.0.